遍历
图的遍历,所谓遍历,即是对结点的访问。一个图有那么多个结点,如何遍历这些结点,需要特定策略,一般有两种访问策略:
- 深度优先遍历
- 广度优先遍历
深度优先
深度优先遍历,从初始访问结点出发,我们知道初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点。总结起来可以这样说:每次都在访问完当前结点后首先访问当前结点的第一个邻接结点。
我们从这里可以看到,这样的访问策略是优先往纵向挖掘深入,而不是对一个结点的所有邻接结点进行横向访问。
具体算法表述如下:
- 访问初始结点v,并标记结点v为已访问。
- 查找结点v的第一个邻接结点w。
- 若w存在,则继续执行4,否则算法结束。
- 若w未被访问,对w进行深度优先遍历递归(即把w当做另一个v,然后进行步骤123)。
- 查找结点v的w邻接结点的下一个邻接结点,转到步骤3。
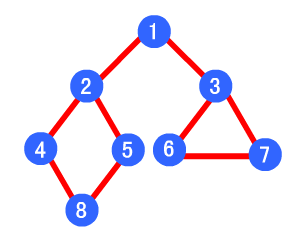
例如下图,其深度优先遍历顺序为 1->2->4->8->5->3->6->7
广度优先
类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来访问这些结点的邻接结点。
具体算法表述如下:
访问初始结点v并标记结点v为已访问。
结点v入队列
当队列非空时,继续执行,否则算法结束。
出队列,取得队头结点u。
查找结点u的第一个邻接结点w。
若结点u的邻接结点w不存在,则转到步骤3;否则循环执行以下三个步骤:
1231). 若结点w尚未被访问,则访问结点w并标记为已访问。2). 结点w入队列3). 查找结点u的继w邻接结点后的下一个邻接结点w,转到步骤6。
如下图,其广度优先算法的遍历顺序为:1->2->3->4->5->6->7->8
Java实现
邻接矩阵图模型类 AMWGraph.java,在原先类的基础上增加了两个遍历的函数,分别是 depthFirstSearch() 和 broadFirstSearch() 分别代表深度优先和广度优先遍历。
|
|
上面的public声明的depthFirstSearch()和broadFirstSearch()函数,是为了应对当该图是非连通图的情况,如果是非连通图,那么只通过一个结点是无法完全遍历所有结点的。
下面根据上面用来举例的图来构造测试类:
|
|

